
Parallelizing Linux Writeback

The Linux kernel’s I/O subsystem has evolved steadily to keep pace with modern storage hardware, with most layers gradually enhanced to exploit parallelism.
Yet one critical piece still remains single-threaded: i.e. the writeback mechanism that flushes dirty pages from page cache to storage. A new patch series from Samsung engineers aims to lift this long-standing bottleneck.
pdflush to per-bdi writeback
Design of writeback mechanism evolved from global pdflush threads in early 2.6 kernels to per-BDI (backing device info) writeback threads. This per-bdi model eliminated problems like contention and request starvation but was designed for an era when storage devices were still largely spinning hard drives or SSDs but mainly with single HW queue. A single writeback thread per backing device made sense back then.
While the per-BDI approach improved upon the global pdflush model, performance limitations remained as storage hardware continued to evolve. Recent developments in memory management have begun addressing some of these bottlenecks. E.g. large folios in filesystems have significantly improved writeback efficiency by allowing writeback thread to process more data per operation.
Example showing writeback processing for a page v/s folio:
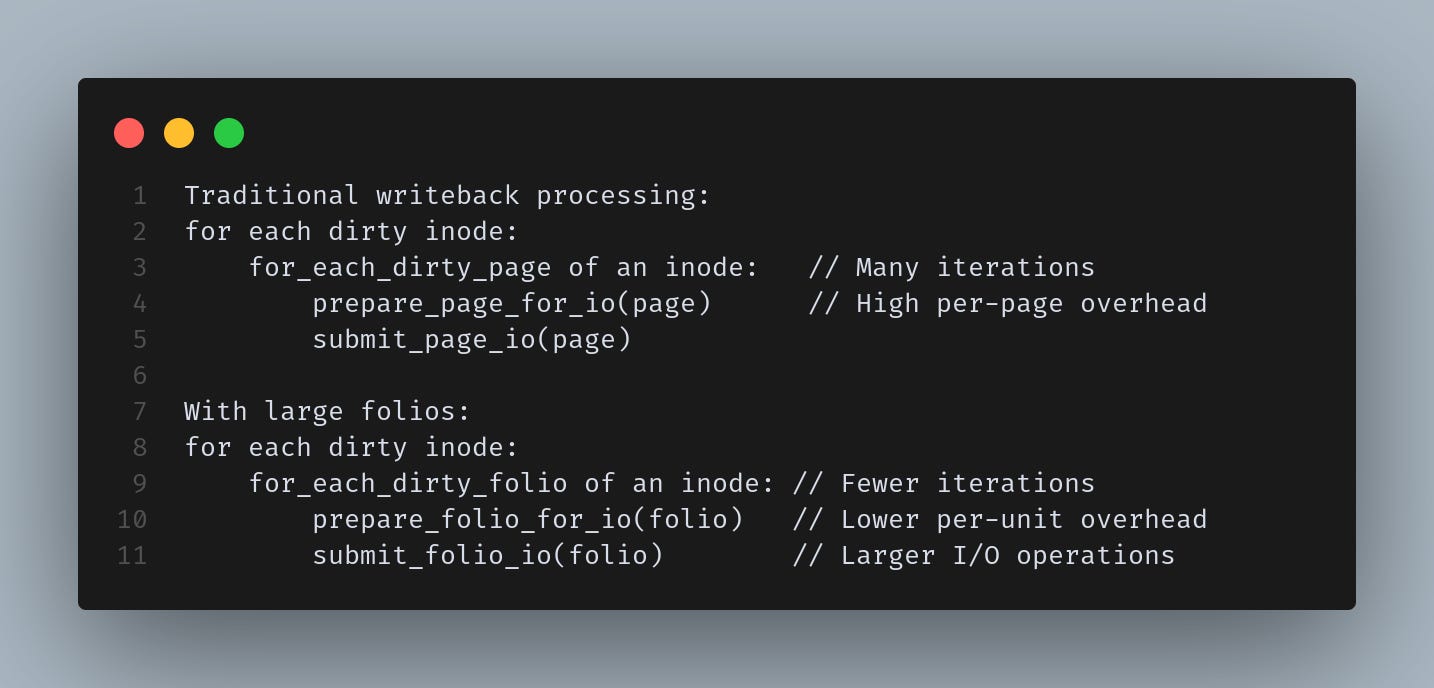
This transformation reduces CPU overhead and enables larger I/O operations that better match modern storage capabilities. All filesystems are now planning to enable use of large folios in their buffered-io path to gain from this benefit.
However, large folios only addresses the efficiency of sequential processing within a single thread. They do nothing to address the fundamental serialization bottleneck of having a single writeback thread per block device, which becomes increasingly problematic as storage devices gain parallel processing capabilities.
The Parallel I/O Stack
The Linux I/O stack has been steadily modernized to exploit parallelism at every layer. Multiple applications can issue write requests to different inodes simultaneously without lock contention, thanks to the virtual file system. Local filesystems such as ext4 and XFS divide their on-disk layout into different allocation groups thus enabling parallel block allocations and metadata operations.
Nearly a decade ago, block layer adopted the multi-queue design with per-CPU submission queues and parallel hardware dispatch queues based on the underlying disk device capabilities. As a result I/O requests can flow concurrently from applications through VFS, filesystem and block layer all the way to the storage drives.
However one notable exception remains: the writeback path still drains dirty pages with a single thread per backing device. Because modern NVMe drives can handle millions of I/O operations per second, optimizing writeback has become the next priority for kernel engineers to fully exploit NVMe throughput for buffered I/O.
Parallelizing Writeback
Now in order to just parallelize writeback, the first thought that would come to anyone’s mind is to add per-CPU parallelism to the per-BDI writeback flusher and then evenly distribute, the amount of work (number of dirty pages) across these per-CPU per-BDI threads.
However there is a subtle problem with this approach. It could cause severe filesystem fragmentation, since dirty pages belonging to the same inode might get written concurrently by multiple per-CPU, per-BDI flushers, thereby negating the purpose of the delayed-allocation techniques that filesystems employ to improve performance and reduce fragmentation. Delayed allocation lets the filesystem wait to allocate blocks until writeback time. At that point contiguous in memory dirty pages can be coalesced into finding a larger on disk extent. This approach avoids allocating individual blocks at the time when write requests are submitted which otherwise can lead to filesystem fragmentation.
So instead what this patch series does is, it creates nr_wb_ctx parallel writeback contexts instead of a single bdi_writeback and affine the inode to only a given writeback context: ensuring that all writeback operations for a specific inode are handled by the same writeback context. Each inode is assigned to a context using inode->i_ino % bdi->nr_wb_ctx logic.
This can preserves delayed allocation effectiveness while distributing different inodes across parallel per-BDI writeback contexts.
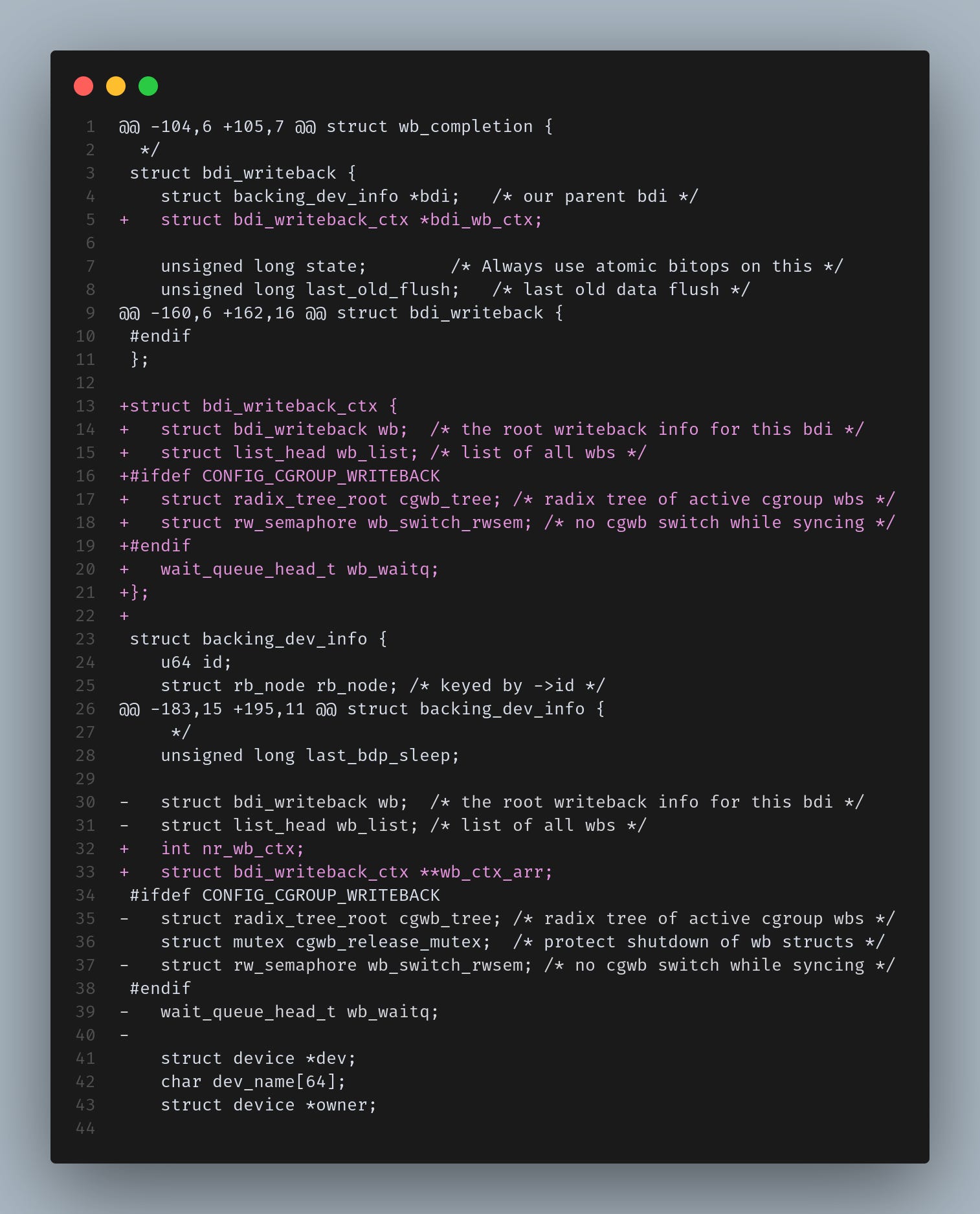
This series introduces a new struct bdi_writeback_ctx which is same as bdi_writeback structure along with few other writeback state information moved into it.
The essential changes made to struct backing_dev_info are:
A new integer
nr_wb_ctxdenoting how many parallel contexts will be used.A dynamically allocated array of pointers to each
bdi_writeback_ctx.Each
bdi_writeback_ctxembeds its ownstruct bdi_writebackand links back to its parent context via abdi_wb_ctxpointer.
This should allow the kernel to spawn and manage multiple parallel writeback context per-BDI, thus eliminating the old single writeback thread per-BDI bottleneck. These two are the heart of the design changes made to make per-BDI writeback mechanism gain parallelism. Rest of the changes are mostly mechanical trying to use bdi_writeback_ctx structure instead of bdi_writeback.
Here is the performance improvement data posted in the patch series which is quite interesting:
IOPS and throughput
===================
We see significant improvement in IOPS across several filesystem on both
PMEM and NVMe devices.
Performance gains:
- On PMEM:
Base XFS : 544 MiB/s
Parallel Writeback XFS : 1015 MiB/s (+86%)
Base EXT4 : 536 MiB/s
Parallel Writeback EXT4 : 1047 MiB/s (+95%)
- On NVMe:
Base XFS : 651 MiB/s
Parallel Writeback XFS : 808 MiB/s (+24%)
Base EXT4 : 494 MiB/s
Parallel Writeback EXT4 : 797 MiB/s (+61%)
We also see that there is no increase in filesystem fragmentation
# of extents:
- On XFS (on PMEM):
Base XFS : 1964
Parallel Writeback XFS : 1384
- On EXT4 (on PMEM):
Base EXT4 : 21
Parallel Writeback EXT4 : 11Conclusion
Although the current proposal addresses one of the most fundamental serialization points in the storage stack but the question still remain about whether the current approach will adequately serve diverse filesystem characteristics or whether a more sophisticated strategy considering filesystem specific geometry (e.g. parallelizing based on per allocation group) will also be needed?
The kernel community's reception of this patch series will likely influence the direction of subsequent buffered I/O optimizations.
Lately through various mailing discussions happening in the filesystems and storage community it is evident that the kernel engineers are finally realizing that there is a need to improve the Linux buffered I/O performance.
Recent developments in this space like filesystems gaining large folio support, introduction of Uncached Buffered I/O also demonstrate that there is definitely a lot to improve in this space, to meet the demands of modern high speed storage hardware.
Fascinating to see writeback finally get a parallelism boost. Do you think per-allocation-group parallelization might still outperform the current inode-affinity approach?